JavaScript之RegExp与正则
本文最后更新于 2025年8月21日 下午
参考:
- https://juejin.cn/post/7153800580077453326
- https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/RegExp
正则的核心
正则就是匹配模式,要么匹配位置,要么匹配字符。划重点,牢记这个核心。
下图是一个字符串:I Love U,箭头表示要匹配的位置,框框表示要匹配的字符(包括空格)。
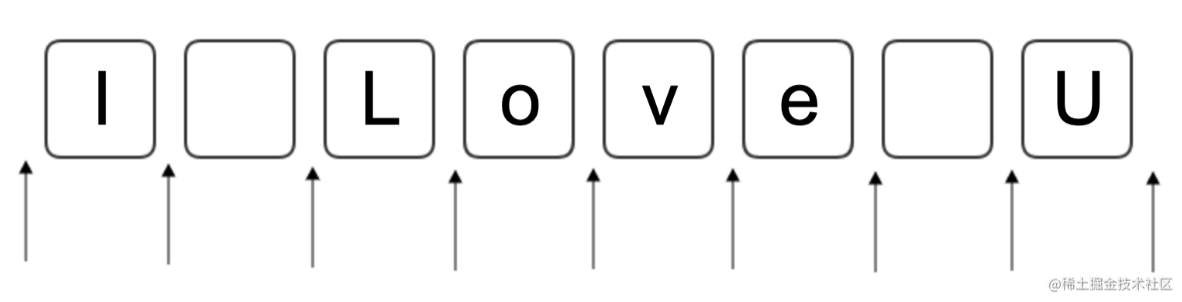
匹配位置
| 模式 | 说明 |
|---|---|
| ^ | 匹配开头的位置,当正则有修饰符 m 时(多行文本),表示匹配行开头位置 |
| $ | 匹配结尾的位置,当正则有修饰符 m 时(多行文本),表示匹配行结尾位置 |
| \b | 匹配单词边界,即匹配上面示例中的 I、Love、U 前后的位置 |
| \B | 匹配非单词边界,与 \b 相反,即匹配上面示例中的 o、v、e 前后的位置 |
| (?=表达式) | 正向先行断言,指在某个位置的右侧必须能匹配表达式 |
| (?!表达式) | 反向先行断言,指在某个位置的右侧不能匹配表达式 |
| (?<=表达式) | 正向后行断言,指在某个位置的左侧必须能匹配表达式 |
| (?<!表达式) | 反向后行断言,指在某个位置的左侧不能匹配表达式 |
匹配以 ‘javascript’ 开头的字符串
匹配以 ‘javascript’ 结尾的字符串
1 | |
匹配有边界的 ‘code’ 单词
1 | |
匹配姓’李’的名字
1 | |
匹配字符
字符
| 模式 | 说明 |
|---|---|
| 字母、数字 | 匹配字符本身 |
| \0 | 匹配 NUL 字符 |
| \t | 匹配水平制表符 |
| \v | 匹配垂直制表符 |
| \n | 匹配换行符 |
| \r | 匹配回车符 |
| \f | 匹配换页符 |
| \xnn | 匹配拉丁字符 |
| \uxxxx | 匹配 Unicode 字符 |
| \cX | 匹配 ctrl+X |
| [\b] | 匹配 Backspace 键 |
字符组
| 模式 | 说明 |
|---|---|
| [abc] | 匹配 “a”、”b”、”c” 其中任何一个字符 |
| [a-d1-4] | 匹配 “a”、”b”、”c”、”d”、”1”、”2”、”3”、”4” 其中任何一个字符 |
| [^abc] | 匹配除了 “a”、”b”、”c” 之外的任何一个字符 |
| [^a-d1-4] | 匹配除了 “a”、”b”、”c”、”d”、”1”、”2”、”3”、”4” 之外的任何一个字符 |
| . | 通配符,匹配除了少数字符(\n)之外的任意字符 |
| \d | 匹配数字,等价于 [0-9] |
| \D | 匹配非数字,等价于 [^0-9] |
| \w | 匹配单词字符,等价于 [a-zA-Z0-9_] |
| \W | 匹配非单词字符,等价于 [^a-zA-Z0-9_] |
| \s | 匹配空白符,等价于 [ \t\v\n\r\f] |
| \S | 匹配非空白符,等价于 [^ \t\v\n\r\f] |
[...] 字符组语法类似 Javascript 中的数组,简单的理解就是正则表达式会匹配 [...] 中的某个字符/表达式,相当于将字符组内的字符遍历匹配。
匹配 ‘Javascript’ 和 ‘javascript’
1 | |
匹配 ‘我爱你’ 或 ‘我想你’ 或 ‘我’ + 数字 + ‘你’
1 | |
匹配’爱’后面不包含’你’
1 | |
量词
贪婪模式――在匹配成功的前提下,尽可能多的去匹配。
惰性模式――在匹配成功的前提下,尽可能少的去匹配。
| 模式 | 说明 | 模式 | 说明 |
|---|---|---|---|
| {n,m} | 连续出现 n 到 m 次(贪婪模式) | {n,m}? | 连续出现 n 到 m 次(惰性模式) |
| {n,} | 至少连续出现 n 次(贪婪模式) | {n,}? | 至少连续出现 n 次(惰性模式) |
| {n} | 连续出现 n 次(贪婪模式) | {n}? | 连续出现 n 次(惰性模式) |
| ? | 等价于 {0,1}(贪婪模式) | ?? | 等价于 {0,1}?(惰性模式) |
| + | 等价于 {1,}(贪婪模式) | +? | 等价于 {1,}?(惰性模式) |
| * | 等价于 {0,}(贪婪模式) | *? | 等价于 {0,}?(惰性模式) |
匹配手机号码,假设手机号码规则如下:
- 必须是 11 位的数字
- 第一位数字必须以 1 开头
- 第二位数字可以是 [3,4,5,7,8] 中的任意一个
- 后面 9 个数是 [0-9] 中的任意一个数字
1 | |
括号
括号主要是用来分组。
| 模式 | 说明 |
|---|---|
| (ab) | 捕获型分组:把 “ab” 当成一个整体,表示 “ab” 至少连续出现一次 |
| (?:ab) | 非捕获型分组:与 (ab) 的区别是不捕获数据 |
| (good | nice) | 捕获型分支结构:匹配 “good” 或 “nice” |
| (?:good | nice) | 非捕获型分支结构:与 (good | nice) 的区别是不捕获数据 |
| \num | 反向引用:比如 \2,表示引用的是第二个括号里的捕获的数据 |
视频文件的后缀名有
.mp4、.avi、.wmv、.rmvb用正则表达式提取所有的视频文件的后缀
1 | |
JS API
Javascript 中可以通过以下两种方式写正则:
- 正则表达式字面量
- 通过构造函数 RegExp 的实例
创建一个正则用于精确匹配字符串 ‘test’:
1 | |
修饰符
| 模式 | 说明 |
|---|---|
| g | 全局匹配,找到所有满足匹配的子串,而不是默认只匹配首次结果(global) |
| i | 匹配过程中,忽略英文字母大小写(ignore case) |
| m | 多行匹配,把 ^ 和 $ 变成行开头和行结尾(multiline) |
| u | 匹配过程中,允许使用 Unicode 点转义符(unicode) |
| y | 开启粘连匹配,正则表达式执行粘连匹配时试图从最后一个匹配位置开始(sticky) |
实例属性
1 | |
flags 标志
flags 属性返回一个字符串,由当前正则表达式对象的标志组成。
标志以字典序排序,从左到右,即”gimuy”。
1 | |
dotAll 标志
dotAll 属性表明是否在正则表达式中一起使用”s”修饰符(引入/s 修饰符,使得可以匹配任意单个字符)。
dotAll 是一个只读的属性,属于单个正则表达式实例。
global 全局匹配
global 属性表明正则表达式是否使用了 “g” 标志。
global 的值是布尔对象,是一个正则表达式实例的只读属性。
“g” 标志意味着正则表达式应该测试字符串中所有可能的匹配。
1 | |
ignoreCase 忽略大小写
ignoreCase 属性表明正则表达式是否使用了 “i” 标志。
ignoreCase 的值是布尔对象,是一个正则表达式实例的只读属性。
“i” 标志意味着在字符串进行匹配时,应该忽略大小写。
1 | |
multiline 多行搜索
multiline 属性表明正则表达式是否使用了 “m” 标志。
multiline 的值是布尔对象,是一个正则表达式实例的只读属性。
“m” 标志意味着一个多行输入字符串被看作多行。
1 | |
source 正则文本
source 属性返回一个值为当前正则表达式对象的模式文本的字符串,该字符串不会包含正则字面量两边的斜杠以及任何的标志字符。
1 | |
sticky 粘连匹配
sticky 属性表明正则表达式是否使用了 “y” 标志。
sticky 的值是布尔对象,是一个正则表达式实例的只读属性。
“y” 标志意味着仅从正则表达式的 lastIndex 属性表示的索引处为目标字符串匹配(并且不会尝试从后续索引匹配)。如果一个表达式同时指定了 sticky 和 global,其将会忽略 global 标志。
1 | |
unicode 点转义符
unicode 属性表明正则表达式是否使用了 “u” 标志。
unicode 的值是布尔对象,是一个正则表达式实例的只读属性。
“u” 标志开启了多种 Unicode 相关的特性。使用 “u” 标志,任何 Unicode 代码点的转义都会被解释。
1 | |
实例方法
1 | |
exec() 搜索匹配
exec() 方法在一个指定字符串中执行一个搜索匹配。返回一个结果数组或 null。
接收一个参数:
- str(必需):要匹配正则表达式的字符串。
如果匹配失败,exec() 方法返回 null,并将正则表达式的 lastIndex 重置为 0。
如果匹配成功,exec() 方法返回一个数组,并更新正则表达式对象的 lastIndex 属性。完全匹配成功的文本将作为返回数组的第一项,从第二项起,后续每项都对应一个匹配的捕获组。数组还具有以下额外的属性:
- index:匹配到的字符位于原始字符串的基于 0 的索引值。
- input:匹配的原始字符串。
- groups:一个命名捕获组对象,其键是名称,值是捕获组。若没有定义命名捕获组,则 groups 的值为 undefined。
- indices (可选):此属性仅在设置了
d标志位时存在。它是一个数组,其中每一个元素表示一个子字符串的边界。每个子字符串匹配本身就是一个数组,其中第一个元素表示起始索引,第二个元素表示结束索引。
当正则表达式设置 g 标志位时,可以多次执行 exec() 方法来查找同一个字符串中的成功匹配。当这样做时,查找将从正则表达式的 lastIndex 属性指定的位置开始。(test() 也会更新 lastIndex 属性)。注意,即使再次查找的字符串不是原查找字符串时,lastIndex 也不会被重置,它依旧会从记录的 lastIndex 开始。
1 | |
test() 是否匹配
test() 方法执行一个检索,用来查看正则表达式与指定的字符串是否匹配。返回 true 或 false。
接收一个参数:
- str(必需):要匹配正则表达式的字符串。
想要知道一个正则表达式是否与指定的字符串匹配时,可以使用 test()(类似 String.prototype.search() ),差别在于 test() 返回一个布尔值,而 search() 返回索引(如果找到)或者 -1(如果没找到)。
想要知道更多信息(然而执行比较慢),可使用 exec() 方法(类似 String.prototype.match() )。和 exec() (或者组合使用)一样,在相同的全局正则表达式实例上多次调用 test() 将会越过之前的匹配。
1 | |
测试
匹配所有符合 XML 规则的标签
1 | |
匹配所有的小数
1 | |
提取下列数据中所有人的生日,使用两个分组,第一个分组提取“月”,第二个分组提取“日”。
- 王伟 1993 年 1 月 2 日
- 张伟 1996.8.24
- 李伟 1996.3.21
- 李秀 1994-7-5
1 | |
编写正则表达式进行密码强度的验证,规则如下:
- 至少一个大写字母
- 至少一个小写字母
- 至少一个数字
- 至少 8 个字符
1 | |
实现一个模板引擎,能够满足如下场景使用:
- let template = 我是,年龄,性别;
- let data = { name: ‘姓名’, age: 18 }
- render(template, data);
- // 我是姓名,年龄 18,性别 undefined
1 | |
写一个方法把下划线命名转成大驼峰命名
1 | |