复杂度分析
本文最后更新于 2025年8月16日 凌晨
参考:
https://juejin.cn/post/6844903750985842695
https://github.com/biaochenxuying/blog/issues/29
https://www.hello-algo.com/chapter_computational_complexity/time_complexity/
什么是复杂度分析
复杂度分析是整个算法学习的精髓。学习数据结构与算法是为了能更快时间、更省空间地解决问题。因此,需要从执行时间和占用空间两个维度来评估数据结构与算法的性能。虽然能用代码准确的计算执行时间,但是也有很多的局限性:
- 数据规模的不同会直接影响测试结果。比如同一个排序算法,排序顺序不一样,那么最后的计算效率的结果会不一样,而如果恰好已经是排序好的了数组,那么执行时间就会更短。又比如如果数据规模比较小,测试结果可能也无法反应算法的性能
- 测试环境的不同也会影响测试结果。比如同一套代码分别在 i3 和 i7 处理器上测试,那么 i7 上的测试时间肯定会比 i3 上的短
所以,需要一个不用准确的测试结果就可以粗略地估计代码执行情况的方法,即复杂度分析。分别用时间复杂度和空间复杂度两个概念来描述性能问题,统称为复杂度。复杂度描述的是算法执行时间和占用空间与数据规模的增长关系。
和具体性能测试相比,复杂度分析有不依赖执行环境、成本低、效率高、易操作、指导性强的特点。掌握复杂度分析,将能编写出性能更优的代码,有利于降低系统开发和维护成本。
大 O 表示法
对于下面代码,估算其执行时间:
1 | |
我们假设每行代码执行的时间都一样记做 t,那么上面的函数中第 2 行需要 1 个 t 的时间,第 3 行 和 第 4 行分别需要 (n+1) 个 t 和 n 个 t 的时间,那么代码总的执行时间为 (2n+2)*t。继续估算下面代码执行时间:
1 | |
第 2 行需要一个 t 的时间,第 3 行需要 (n+1) 个 t 的时间,第 4 行和第 5 行分别需要 (n2 + 1) 个 t 和 n2 个 t 的时间,那么代码总的执行时间为 (2n2+n+3)*t 的时间。
可以得出规律,代码的总执行时间 T(n) 与每行代码的执行次数成正比:T(n) = O(f(n))。在这个公式中,T(n) 表示代码的执行时间,n 表示数据规模的大小,f(n) 表示代码关于 n 所执行次数总和,O 表示代码的执行时间 T(n) 与 f(n) 表达式成正比。所以,上面两个函数的执行时间可以标记为 T(n) = O(2n+1) 和 T(n) = O(2n2+n+3)。
这就是大 O 时间复杂度表示法,它不代表真正的执行时间,而是表示算法执行时间随数据规模增长的变化趋势,所以也叫渐进时间复杂度,简称为时间复杂度。由于时间复杂度描述的是算法执行时间与数据规模的增长变化趋势,所以常量阶、低阶、系数实际对这种增长趋势不产生决定性影响,所以做时间复杂度分析时忽略这些项。所以上面的代码执行时间简单标记为 T(n) = O(n) 和 T(n) = O(n2)。
时间复杂度分析
只关注循环执行次数最多的一段代码
1 | |
第 3 和第 4 行执行次数最多,分别执行 n 次,又忽略常数项,故此段代码的时间复杂度就是 O(n)。
加法法则:总复杂度等于量级最大的那段代码的复杂度
1 | |
- 第一段 for 循环的时间复杂度为 O(n2)
- 第二段 for 循环执行了 1000 次是个常数量级,尽管对代码的执行时间有影响,但当 n 无限大时就可以忽略,因为它本身对增长趋势没有影响,所以这段代码的时间复杂度可以忽略
- 第三段 for 循环的时间复杂度为 O(n)
综上,取最大量级,所以整段代码的时间复杂度为 O(n2)。
乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
1 | |
单独看 total 函数的时间复杂度就是为 T1(n)=O(n),但是考虑到 f 函数的时间复杂度 T2(n)=O(n)。 所以整段代码的时间复杂度为 T(n) = T1(n) * T2(n) = O(n*n)=O(n2)。
多规模加法:多个参数控制多个循环相加的次数,二者复杂度相加
1 | |
因为我们无法评估 m 和 n 谁的量级比较大,所以就不能忽略掉其中一个,这个函数的复杂度是有两个数据的量级来决定的,所以此函数的时间复杂度为 O(m+n)。
多规模乘法:多个参数控制多个循环嵌套的次数,二者复杂度相乘
1 | |
同理,此函数的时间复杂度为 O(m*n)。
常用的时间复杂度
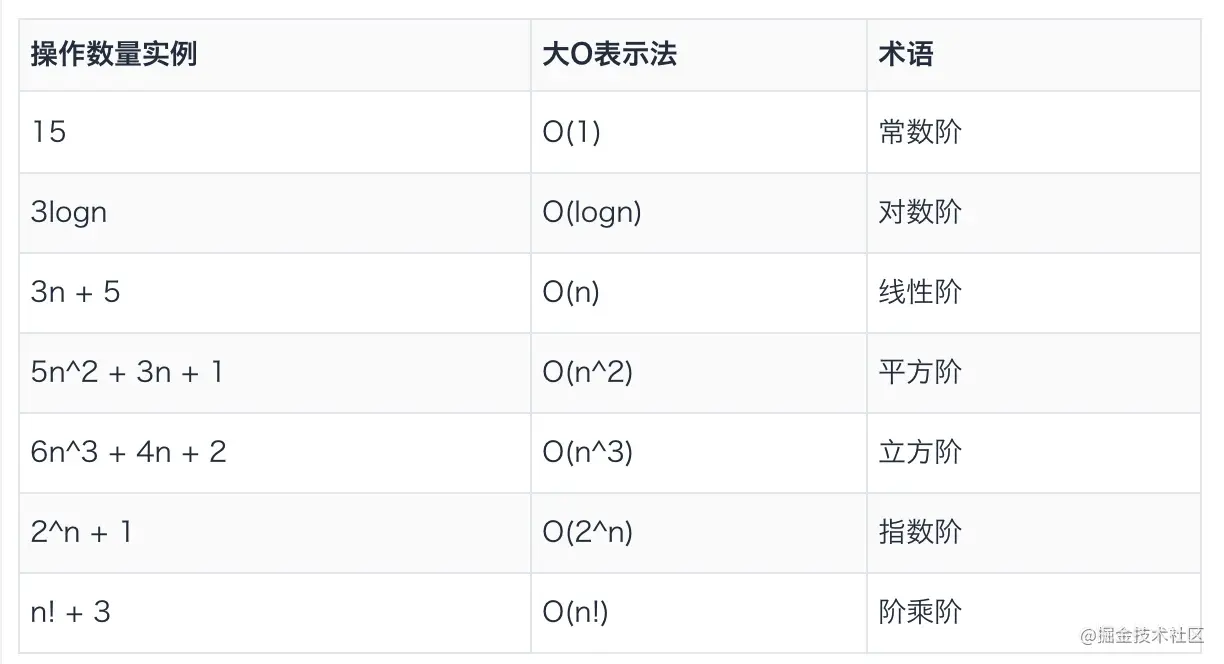
上图可以粗略的分为两类:多项式量级和非多项式量级。
多项式量级:随着数据规模的增长,执行时间按照多项式的比例增长。包括 O(1)(常数阶)、O(logn)(对数阶)、O(n)(线性阶)、O(nlogn)(线性对数阶)、O(n2) (平方阶)、O(n3)(立方阶)。
非多项式量级:随着数据规模的增长,执行时间急剧增加。这种算法是非常低效的算法。包括 O(2n)(指数阶)和 O(n!)(阶乘阶)。
常用的时间复杂度所耗费的时间从小到大(效率从高到低):
O(1) < O(logn) < O(n) < O(nlogn) < O(n2) < O(n3) < O(2n) < O(n!) < O(nn)
O(1)
1 | |
即使 for 循环执行了 1000 次,但是代码的执行时间不随 n 的增大而变化,所以时间复杂度为 O(1)。
O(logn)
1 | |
上面两个函数都有一个相同点,变量 i 从 1 开始取值,每循环一次乘以 2,当大于 n 时,循环结束。实际上,i 的取值就是一个等比数列。所以只要知道 x 的值,就可以知道这两个函数的执行次数。那由 2x = n 可以得出 x = log2n,所以这两个函数的时间复杂度为 O(log2n)。
实际上不管是以 2 为底、以 3 为底,还是以 10 为底,我们可以把所有对数阶的时间复杂度都记为 O(logn)。因为对数之间是可以互相转换的,log3n = log32 * log2n,所以 O(log3n) = O(C * log2n),其中 C = log32 是一个常量,可以忽略。因此,在对数阶时间复杂度的表示方法里,我们忽略对数的 “底”,统一表示为 O(logn)。
O(nlogn) 的含义就很明确,时间复杂度为 O(logn) 的代码执行了 n 次。
时间复杂度分类
算法的时间效率往往不是固定的,而是与输入数据的分布有关。假设输入一个长度为 n 的数组 nums,其中 nums 由从 1 至 n 的数字组成,每个数字只出现一次;但元素顺序是随机打乱的,任务目标是返回元素 1 的索引。可以得出以下结论:
- 当
nums = [?, ..., 1],即末尾元素是 1 时,需要完整遍历数组,达到最差时间复杂度 O(n) - 当
nums = [1, ?, ...],即首个元素为 1 时,无需继续遍历数组,达到最佳时间复杂度 O(1)
值得说明的是,我们在实际中很少使用最佳时间复杂度,因为通常只有在很小概率下才能达到,可能会带来一定的误导性。而最差时间复杂度更为实用,因为它给出了一个效率安全值,让我们可以放心地使用算法。
从上述示例可以看出,最差时间复杂度和最佳时间复杂度只出现于“特殊的数据分布”,这些情况的出现概率可能很小,并不能真实地反映算法运行效率。相比之下,平均时间复杂度可以体现算法在随机输入数据下的运行效率。
对于部分算法,我们可以简单地推算出随机数据分布下的平均情况。比如上述示例,由于输入数组是被打乱的,因此元素出现在任意索引的概率都是相等的,那么,算法的平均循环次数就是数组长度的一半 n/2,平均时间复杂度为 O(n/2)。
但对于较为复杂的算法,计算平均时间复杂度往往比较困难,因为很难分析出在数据分布下的整体数学期望。在这种情况下,通常使用最差时间复杂度作为算法效率的评判标准。
空间复杂度分析
空间复杂度的全称是渐进空间复杂度,表示算法存储空间随数据规模增长的变化趋势。
空间复杂度通过计算算法所需的存储空间实现,计算公式记作:S(n) = O(f(n))。其中,n 为数据规模的大小,S(n) 为代码的存储空间,f(n) 为代码关于 n 所占存储空间的函数,O 表示代码的存储空间 S(n) 与 f(n) 表达式成正比。
1 | |
空间复杂度和时间复杂度类似,忽略掉常数量级,每次数组赋值都会申请一个空间存储变量,所以此函数的空间复杂度为 O(n)。
常见的空间复杂度有 O(1)、O(n)、O(n2), 其他的很少会用到。